Java部分

Java部分
CalyeeHashMap理解
1.说说你对hash算法的理解
其实 hash 算法的本质上是对输入任意长度的输入进行编码,然后隐射成固定长度的输出。
追问:hash算法任意长度的输入 转化为了 固定长度的输出,会不会有问题呢?
在程序中碰到 value 在经过计算后得到的 hash 值和之前的一样,这个其实就是 hash 冲突。
追问:hash冲突能避免么?
避免理论上是不能避免的,比如我列举一个场景,就是我现在有 10 个苹果,但是抽屉只有 9 个,我要想全部放进去,那么肯定是有一个抽屉会多放的。所以只能尽量的避免,但是不可能完全避免的。
2.你认为好的hash算法,应该考虑点有哪些呢?
第一点:这个hash算法 它一定效率得高,要做到长文本也能高效计算出hash值嘛。
第二点:不能逆推原文
第三点:hash 后,尽可能的使其排列比较分散,尽可能的减少冲突
3.HashMap中存储数据的结构是什么样的呢?
java8 中,数组 + 链表/红黑树
然后每一个数据单元其实就是一个 Node,然后 Node结构中有key字段、有value字段、还有next字段、还有hash字段。
然后 next 字段其实就是为了处理 hash 冲突而建立的,然后发生了冲突,那么当前节点的 next 指针就会指向发生冲突的那个节点,然后连接上来。
4.创建HashMap时,不指定散列表数组长度,初始长度是多少呢?
如果没有指定情况下,hashmap 的默认长度为 16
追问:散列表是new HashMap() 时创建的么?
不是,创建散列表的时候,其实她是懒加载的,只有当第一次 put 的时候才会创建。
5.默认负载因子是多少呢,并且这个负载因子有什么作用?
默认的负载因子是 0.75,那么也就是说是 75%。
作用其实就是用来扩容用的,比如我们当前的长度为 16,那么达到需要扩容的阈值了,然后就是扩容 16*0.75 = 12,那么她就是以 12 为单位进行扩容。
6.链表转化为红黑树,需要达到什么条件呢?
两个指标:1. Node 节点长度大于 8,2. 散列表长度大于 64
如果 node 长度大于 8,此时散列表的长度是大于 64 的,那么就会先扩容散列表然后取消本次链表翻转的,这是发生 resize 散列表扩容代替链表翻转红黑树升级。
7.Node对象内部的hash字段,这个hash值是key对象的hashcode()返回值么?怎么得到的呢?
不是,这个 hash 值是 key.hashCode( )得到的,其中它的操作是 高 16 位 ^ 低 16 位得到的新值。(异或)
追问:hash字段为什么采用高低位异或?
这个主要还是得考虑 hash 寻址算法的缘故,首先我们都知道,散列表的长度尽可能的都是 2 的 n 次方,比如 16,32,64 等,然后寻址算法是 hash & (table.length - 1),我们知道table.length 是 2^n,那么length转化为二进制后,一定是(1)是高位,然后低位全部是(0),这种数字 -1 也比较特殊,比如 16-1 就是 1111,任何(数)与这种高位全部为0,低位都是一串1的数,按位与之后它得到的这个数值一定是>=0 且<=这个二进制数,然后带上下标为 0 的 slow 则刚刚好为 2 的 n 次方。
8.🌈HashMap put 写数据的具体流程,尽可能的详细点!
写数据一共分为四种情况:
- slow 为空(没有初始数据)
- slow 不为空,其实就是当 slow 为一个节点的时候(没有链化)
- slow 已经链化
- slow 已经树化
- 然后对于第一种情况:那就是直接 put 进来的值封装成一个 node 节点放入 value 即可。
- 对于第二种情况:只有一个节点,那还是先封装,如果当前节点的 key 是已经存在的,那么则直接替换 value 即可,否者就是冲突,那么直接使用尾插法。
- 如果是已经链化了,那么其实跟第二种处理很相识,首先就是遍历迭代查找 node,如果有则替换,没有则插入到尾部,此时还是要判断是否达到树化阈值。
9.红黑树的写入操作,是怎么找到父节点的,找父节点流程?
红黑树的写入操作,对于红黑树来说(首先得说明它的结构,TreeNode:value、left、right、parent、red),然后红黑树是满足二叉排序树的所有特性的,所以找到父节点其实是和二叉排序树是完全一致的,
对于数据来说:左节点小于当前节点,右节点大于当前节点,然后每次搜索一层就可以过滤掉一半的数据。
插入:如果探测节点一直向下查找没有找到其值,那么此时的位置其实就是可插入的位置(然后就是插入父节点的左边或者右边即可),然后根据插入节点的值可能会打破节点的平衡,那么此时则需要一个红黑树的平衡算法。/ 如果探测节点发现有 TreeNode#key 一致的节点,那么直接替换其 value 即可。
10.🌈红黑树的原则有哪些呢(性质)?
1.每个结点要么是红的要么是黑的。
2.根结点是黑的。
3.每个叶结点(叶结点即指树尾端NIL指针或NULL结点)都是黑的。
4.如果一个结点是红的,那么它的两个儿子都是黑的。
5.对于任意结点而言,其到叶结点树尾端NIL指针的每条路径都包含相同数目的黑结点。
正是红黑树的这5条性质,使一棵n个结点的红黑树始终保持了logn的高度,从而也就解释了上面所说的“红黑树的查找、插入、删除的时间复杂度最坏为O(log n)”这一结论成立的原因。
11.JDK8 HashMap 为什么引入红黑树?解决什么问题?
引入红黑树其实就是为了解决上面的第三点,它如果过长的节点就是会发生链化问题,我们知道链表的查询,它是需要一个一个去遍历的,它不像数组一样它是连续的。
然后至于为什么阈值是 8,因为当链表中的元素数量达到8时,使用红黑树进行查找的效率会超过链表。具体来说,当链表中的元素数量为8时,平均查找长度为(1+8)/2=4。而红黑树的平均查找长度为log(8),大约是3。因此,将链表转换为红黑树可以提高查找效率。
12.HashMap 什么情况下会触发扩容呢?
扩容肯定是在除非写入操作的时候,然后在 hashmap 的内部有一个计算数据量的字段,它达到扩容阈值就会触发扩容
1 | /** |
追问:触发扩容后,会扩容多大呢?算法是什么?
扩容其实是有一个规则的(它肯定是要满足 2 的次方),其次它每次是根据上一次的 tableSize 位移运算得到的,左移一位:例如 16<<1 => 32
追问:为什么采用位移运算,不是直接 * 2?
其实在计算机的底层是不支持乘除操作,最后在指令层都会转换为加分运算的,我们直接使用位移操作,这样对 cpu 更加友好,其次更简洁高效。
13.🌈HashMap扩容后,老表的数据怎么迁移到扩容后的表的呢?
对于迁移操作,其实就是桶位推进迁移的操作,主要还是得看当前的状态吧(四种)
第一种是 slot 存储的是 null,第二种是存储的是单个的 node 没有链化,第三种是 node 节点已经链化了,第四种是已经形成了红黑树。
对于第一种情况不需要处理,我们只需要处理后面的三种情况了。
对于单个节点操作,当发现 node 节点的 next 指针为 null,那么直接迁移即可,在新表通过 tableSize 计算位置即可,
对于已经链化的操作(已经发送过冲突):此时需要把当前保存的链表拆分成两个链表,分别是高位链和低位链(此处需要重点研究)
- 低位链(Low-order chain):
- 当HashMap扩容时,会创建一个新的哈希表,其容量是原哈希表容量的两倍。
- 在这个过程中,每个键值对会根据新的哈希表容量重新计算其哈希值。
- 如果某个键值对在新哈希表中的位置与旧哈希表中的位置相同(即新哈希值与旧哈希值在新的容量下最低的有效位是相同的),那么这个键值对会被放到“低位链”中。
- 换句话说,低位链包含了那些不需要移动或者只需要移动到“当前索引+旧容量”位置的元素。
- 高位链(High-order chain):
- 与低位链相对,高位链包含了那些在新哈希表中位置与旧哈希表位置不同的键值对。
- 这些元素在新哈希表中的位置是旧索引位置加上旧哈希表的容量。
- 高位链的元素需要被重新放置到新的位置上。
对于低位链来说:它的高位是 0,那么在迁移到新表的时候,这个 slot 下标和老的是一样的。
对于高位链来说:它的高位是 1,所以说在迁移到新表之后,其实它是要在进行一次运算的(其中是老表的位置+老表的 size 长度)比如是老表的 size 是 16,此时他的位置是 8,那么扩容后的结果则是 24 的桶位置。
14.HashMap扩容后,迁移数据发现该slot是颗红黑树,怎么处理呢?
其实红黑树的结构它依然是保留了 next 字段,也就是说,其实它内部还是维护着一个链表(新增删除都需要进行维护),只不过查询的时候是使用的红黑树进行检索。为什么还维护着一个链表呢,因为在拆分链表转换为红黑树的时候需要使用到这个结构,它也是跟高位和低位进行操作的。
唯一不同的就是,如果你的 TreeNode 的长度是小于 6 的时候,它直接转换为链表存储在新的表中即可,如果拆分出来还是大于 6 的则需要转换为红黑树(重建红黑树)
扩展
HashMap 的 get()流程
源码
1 | public V get(Object key) { |
流程图
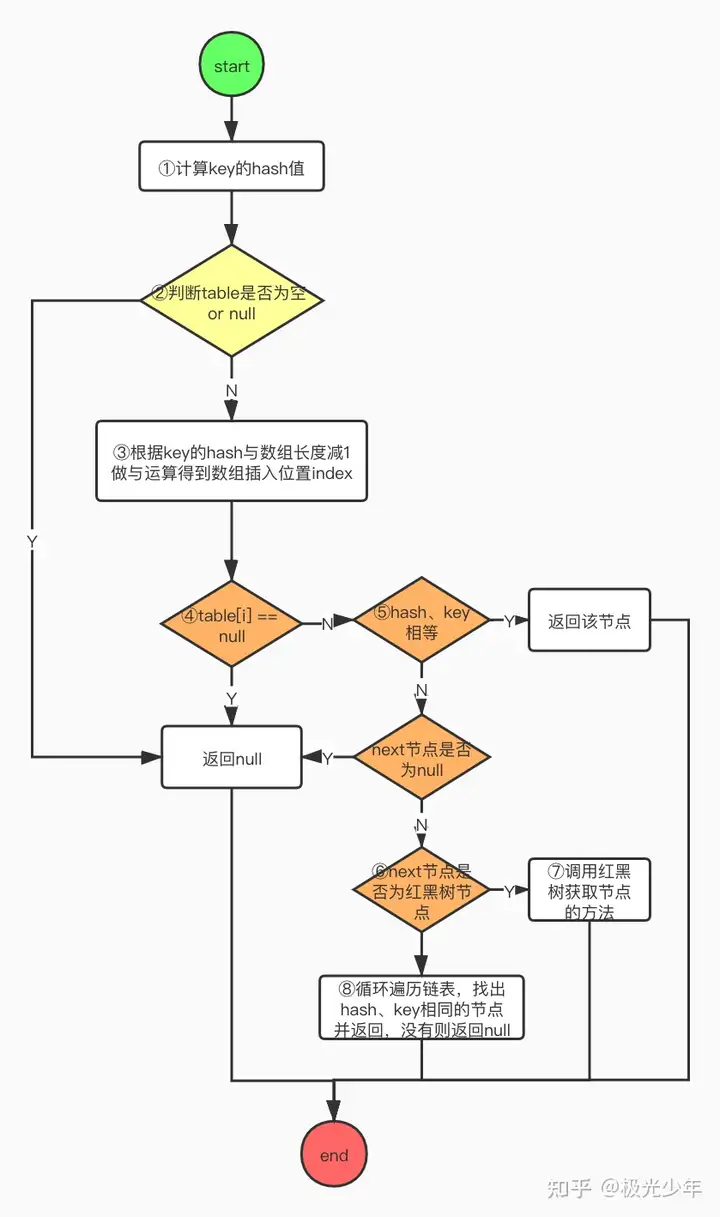
①第一步和put方法一样,获取key的hash值;
②判断数组table是否为空;
③如果数组为空,直接返回null,结束查找;如果数组不为空,则将hash值与数组长度减1做&运算确定数组位置;
④取出该位置的节点判断是否为空,如果为空,直接返回null,结束查找;
⑤判断当前节点的hash、key与待查找的hash、key是否相等,如果相等返回该节点,查找结束;如果不相同则判断当前节点的后继节点是否存在,不存在则直接返回空,结束查找;
⑥若存在则需判断节点类型属于链表节点还是红黑树节点;
⑦如果是红黑树节点则调用红黑树查找方法;
⑧如果是链表节点,则整条遍历链表,找到key和hash值相同的节点则返回,没有找到则返回空。
AQS
AQS 类定义以及 Node 节点数据结构说明
众所周知 AQS 是AbstractQueuedSynchronizer 的简称
然后他有两个重要的属性
- state: volatile int state
它代表着一个同步状态,他在不同的实现子类中有不同的实现
例如在ReentrantLock 中 state = 1 代表当前共享资源已经被加锁,> 1 则代表被多次加锁
然后对于 state 的操作,他有三个方法
1 | final int getState(); |
其实compareAndSetState()我们可以看做 CAS
CAS: 全称是CompareAndSwap,是一种用于在多线程环境下实现同步功能的机制。CAS操作包含三个操作数:内存位置、预期数值和新值.
CAS的实现逻辑是将内存位置处的数值与预期数值想比较,若相等,则将内存位置处的值替换为新值。若不相等,则不做任何操作。
- Node 节点
其中 Node 节点结构如下:(双向链表 同步队列)
| int | waitStatus |
|---|---|
| Node | prev |
| Node | next |
| Thread | thread |
对于 Node 节点,做如下解释:当一个线程拿不到锁的时候,他就会被添加到 Node 节点的双向链表中
+——+ prev +—–+ +—–+
head | | <—- | | <—- | | tail
+——+ +—–+ +—–+
其中 Head 与 Tail 指针是用于标记阻塞线程节点的头尾指针,中间的节点其实就是 Node 节点,可以理解为队列,一个一个的取,处理完成则去除当前线程节点,然后指向下一个节点。
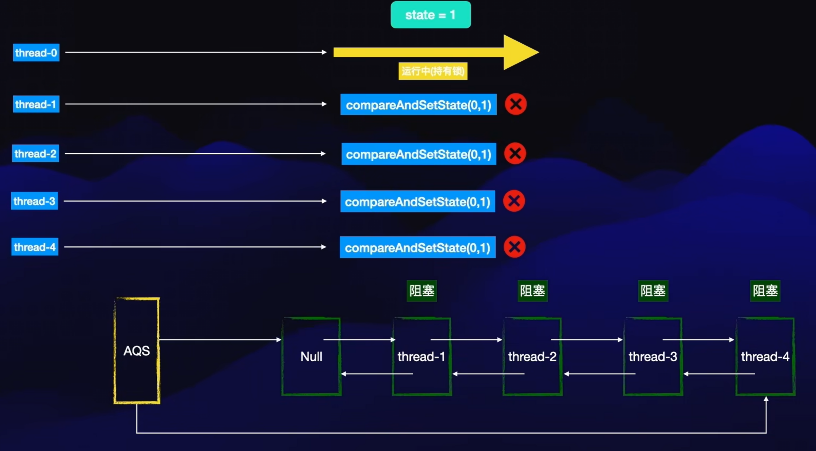
如果 thread-0 执行完毕后,他对应的 state = 0,然后释放锁,此时 AQS 队列中排队等待的线程则会按连接顺序依次出队列。此时 thread-1 不是说 thread-1 释放锁了他就直接拿到锁,他还是像之前没有拿到锁一样,通过 cas 进行修改 state 值然后拿锁。假设 thread-1 成功持有锁了,那么 aqs 维护的队列就会让队头元素出队,然后刚刚获取锁的线程成为头结点。然后一直重复入队出队的操作。
:持有锁修改 state 为 1,释放锁修改 state 为 0
从ReentrantLock的非公平独占锁实现来看AQS的原理
通过了解类 AbstractQueuedSynchronizer 我们可以知道他是一个抽象类,其中他还有一个父类AbstractOwnableSynchronizer
1 | public abstract class AbstractOwnableSynchronizer implements java.io.Serializable { |
其中 AQS 中比较重要的成员变量有:1. head:头指针 2. tail:尾指针
1 | public abstract class AbstractQueuedSynchronizer |
state:在前一节已经解释过
spinForTimeoutThreshold:超时中断
其中AQS 中还有一个 Node 静态内部类代码块
1 | static final class Node { |
AQS如何实现加锁的
我们通过追踪lock()方法 然后 追踪ReentrantLock
1 | Lock lock = new ReentrantLock(); |
然后可以发现 其实他是委托给Sync实现的
1 | public void lock() { |
我们知道,ReentrantLock是可以使用公平锁和非公平锁(默认)两种形式,那么Sync其实在他的类里面就是有两种表现形式。
追踪默认非公平锁实现
1 | static final class NonfairSync extends Sync { |
然后我们可以发现有两个重要的函数出现了,CAS(CompareAndSwap)、Acquire
acquire
1 | public final void acquire(int arg) { |
- tryAcquire
当前方法其实我们可以理解为,在公路上有红绿灯,其中红灯停是对于人类认为并制定的规则,那么我们这个具体传入多少其实就是看内部自己的实现是如何的。
那么其实现类就是,除了实现AQS的state状态以外,还需要提供一些方法用于实现对state的定义。
但是话是这么说,我们通过跟踪 tryAcquire方法我们可以发现,在当前类的父类AQS里面,它是长这样的。
1 | protected boolean tryAcquire(int arg) { |
我们知道,AQS其实就是一个抽象类,但是在以往的学习中,我们的抽象类的实现一般都是继承全部的父类方法(描述为抽象方法)的?但是我们可以看到上面那个,它没有使用abstract去定义它,子类不是必须去对这个方法进行声明定义的,也就是说:我们只有需要实现什么再对其进行重写即可。
其次我们在对AQS进行搜索关键字abstract,我们可以发现当前关键字仅仅声明在类定义中。这种也是一种设计规范,值得学习。
AQS设计的初衷:为了帮助其他的同步组件设计一个规范基础,所以他不希望别人直接可以拿来就使用,而是需要在你的具体场景根据规范去具体实现。
为什么没有设计抽象方法:因为可能有些场景有些不需要去被实现,此时如果子类还调用了不需要实现的方法,那么就会抛出异常。
然后 ReentrantLock 他的 tryAcquire 我们可以发现其实默认是返回的是一个 非公平的尝试获取锁(nonfairTryAcquire)
1 | final boolean nonfairTryAcquire(int acquires) { |
- acquireQueued
如果上面那个获取锁失败,然后就会走到这个逻辑。
1 | // 方法签名 |
addWaiter(Node.EXCLUSIVE)执行结果作为acquireQueued的入参
1 | // 没有打包的节点会被封装保存到队列里面 |
其实这个enq可以和上面的那个方法合并,我们可以在java9看到其实此时已经没有了这个方法了。
acquireQueued方法
1 | // 方法定义(其实就是把获取锁失败的线程node给添加同步队列里面去) |
到了这里,可能对于这个acquireQueued的内部逻辑不太理解,没关系,其实就是将没获取锁成功的锁节点加入到同步队列中。
那么此时我们则对最开始的node状态会有所了解了(加上int默认的0,其实是有五个状态的)
1 | /** 当前等待的线程可能因为其他原因而取消 */ |
那么从lock方法进来构建的同步队列中,节点的状态不可能为1的,他是被取消的。
那么 -1是肯定有可能的,因为他用于唤醒下一个节点的。
-2 (CONDITION)是用于条件队列中,我们的队列并不是条件队列,那么肯定是用不到该状态的
-3 (PROPAGATE)用于共享模式下的一个状态,对于ReentrantLock是独占锁,那么肯定是用不到该状态的
– 此处可以跳过了–
这个我们知道了之后,我们看到有方法shouldParkAfterFailedAcquire
1 | private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) { |
compareAndSetState()
JDK动态代理 案例
**需求: ** 简单的实现增强(AOP)
JDK动态代理只能代理实现了接口的类,不支持对类的直接代理
在此提供一个接口和一个实现类, 需要对接口实现类中的方法进行增强
1 | // Interface |
1 | // Implement |
增强部分:
首先需要自定义类实现InvocationHandler接口, 其次重写invoke方法, 通过invoke方法进行代理: 案例如下:
1 | public class ProxyHandler implements InvocationHandler { |
- 对于24-26行: 对于方法名为 hello进行增强, 此处以前置增强为例, 在方法执行(invoke)前, 执行自定义方法(showTime)显示时间
测试方法:
1 | public class Main { |
输出如下:
1 | com.hang.HelloImpl@61bbe9ba |
可以很明显的看到, 在hello方法执行前, 输出了自定义增强方法showTime
此时需要观察生成代理字节码类可以在测试中添加
1 | System.getProperties().put("sun.misc.ProxyGenerator.saveGeneratedFiles","true"); |
添加该行后, 在当前Module的同目录下会生成文件夹为com.sum.proxy ,文件夹内会生成字节码$Proxy0 … $Proxy20 … 数字部分可变
以当前案例生成的字节码为例: ($Proxy0.class)
1 | public final class $Proxy0 extends Proxy implements IHello { |
通过该字节码文件可以很明显的发现一共生成了 5个 Method (两个为刚刚定义的方法, 三个(1.equals 2.toString 3.hashCode)为默认生成的)
在代码尾部的static部分, 生成了方法上述的5个方法
以当前字节码文件中的 hello()为例 (因为我们对该方法增强了):
该方法主要逻辑为执行super.h.invoke(this, m3, (Object[])null);
该方法很明确就是调用父类的 InvocationHandler
1
2// the invocation handler for this proxy instance.
protected InvocationHandler h;然后调用invoke, 这个invoke不就是我们案例中重写了的invoke吗?
总结: 通过代理接口实现接口方法, 当调用时执行代理类中的同名方法然后回调到我们自定义的invoke, 在该方法内可以实现增强(前置,后置,环绕)
JDK谓词
直接上案例
1 | List<String> ns= Arrays.asList("calyee blog","cal","ccaaalyyyyeeee"); |
追踪Predicate
1 |
|
当前案例为: 筛选长度大于3的对象
其中removeIf方法为传入一个谓词对象, 通过谓词条件构造筛选条件, 然后重复遍历(类似于构造if-else判断)
所以: 谓词工厂就是一个判断
消费者回调
在Java编程中,有时需要对某个对象进行操作或者处理,而这个操作可能是非常灵活的。Java 8引入了函数式编程的特性,其中的一个重要接口就是Consumer接口
例如在Java中比较常见的foreach
1 | default void forEach(Consumer<? super T> action) { |
通过阅读我们可以知道,传入了一个集合,然后对每一个元素进行遍历,然后再accept(t)回调消费,像这样回调就能拿到每一个对象的值。
那么后续的回调就是通过匿名函数调用
这里还能实现类似的Spring AOP的功能(增强顺序),情景:通过递归遍历链表
1 | // Function |
Java8特性
Stream
直接代码奉上
1 | Map<Integer, List<ByYearInnerDataVO>> optimizedData = yearIndicatorData.entrySet().stream() |
用的多的就是
map() - 过程中
map是可以对里面的数据进行处理的,同样使用的还有peek( ),不过这个 笔者测试好像不会对内部结构改变(不常用)
1 | indicator.stream().map(indicatorName -> { |
groupBy() - 结果
1 | Map<Integer, List<OurBean>> groupByYear = |
然后就可以得到以年份为key的List对象
其他
笔者今天看到每日一题有解答者使用了IntStream
1 | int result = IntStream.of(arr).min().getAsInt(); // 通过intstream流获取arr数组的最小值并且获取 |
然后通过分析,笔者发现这个里面还有DoubleStream等类,然后点进去发现他们继承自BaseStream<T, TStream>其中T代表例如int、double这种数据类型
然后再分析,其实就是stream流的基础操作,这个只不过可以直接处理我们已经明确的基础数据类型数据
Optional
好用,可以避免一些判空的操作
1 | // 如果list.get(i)为空,那么就是执行后面的语句 |
BigDecimal
浮点类型
高精度之精度丢失
1 | // 用法一 |
对应的结果如下:
a: 0.01000000000000000020816681711721685132943093776702880859375
b: 0.01
那么: 在new BigDecimal的时候传入的已经是浮点类型( 近似值 )了, 而在使用valueOf的时候, 通过阅读源码可知
1 | public static BigDecimal valueOf(double val) { |
在valueOf的方法内部, 调用了Double.toString方法转换成为了字符串, 转换成为字符串就不存在进度丢失问题 (因为可以使用字符串模拟高精度实现计算: 梦回c语言高精度实现)
那么我们需要使用则: (两个方向)
- 创建对象时, 构造函数传字符串
- 使用BigDecimal.valueOf传值初始化对象
精度设置
其实就是四舍五入的问题
1 | BigDecimal a = new BigDecimal("1.0"); |
例如我们需要运算
1 | a.divide(b); |
然后就会抛出异常: ArithmeticException
因为它(结果)是一个无限循环小数, 它不能转换成为我们预期的精确数字
所以需要指定精度
1 | BigDecimal c = a.divide(b, 4,RoundingMode.HALF_UP); |
- 4: 四位小数
- RoundingMode.HALF_UP: HALF_UP-> 大于一半则向上取整
故结果为: 0.3333
其中RoundingMode还有很多枚举, 自行查阅
浮点比较
比较BigDecimal值的大小
1 | BigDecimal a = new BigDecimal("0.01"); |
然后有两种比较方法
1 | a.equals(b) |
其中一看好像没什么区别, 查阅源码( equals )可知
1 |
|
compareTo则是实现比较值的大小, 返回的值为-1(小于),0(等于),1(大于)
我们可以知道, 如果在严格要求精度的情况下, 使用equals
如果仅考虑值的大小则考虑使用 compareTo
输出格式化
此处仅给出几个示例:
1 | NumberFormat currency = NumberFormat.getCurrencyInstance(); //建立货币格式化引用 |
输出:
1 | 金额: ¥59,988.24 |
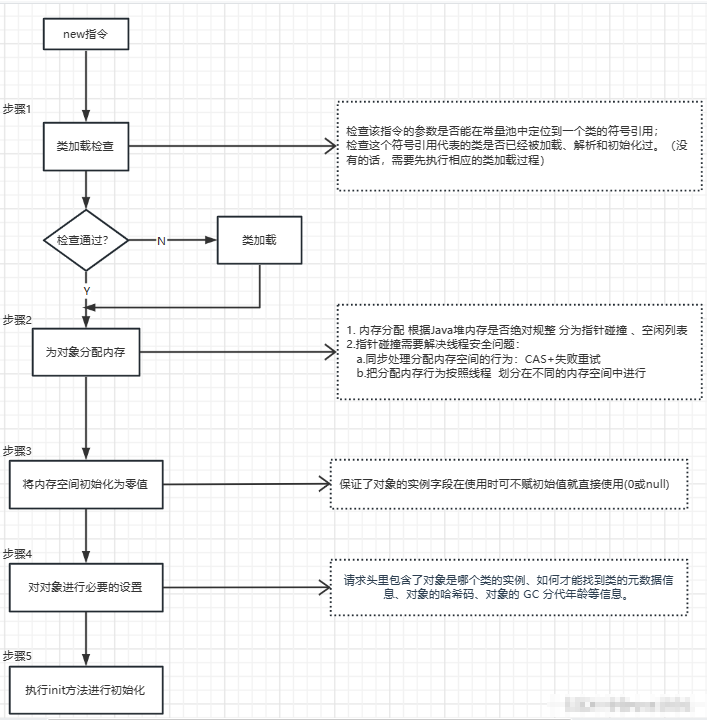
Java 对象创建的过程
- 先进行类加载,查看是否被加载过
- 为对象分配内存
- 初始化内存空间
- init 对象创建