SpringCloud

SpringCloud
Calyee微服务篇章
SpringCloud
入门理论
CAP理论
CAP即:
- Consistency(一致性) 对某个指定的客户端来说,读操作保证能够返回最新的写操作结果
- Availability(可用性) 非故障的节点在合理的时间内返回合理的响应(不出现错误或超时)
- Partition tolerance(分区容忍性) 某一块出现故障不影响其另外的运行
经常用微服务的小伙伴应该知道, CAP就是说一个分布式系统不可能同时满足C、A、P这三个特性
对于分布式架构项目来说, 一般P是肯定满足的, 那么仅仅剩下C和A了
- CP: 满足一致性和分区容忍性,牺牲可用性。当网络分区发生时,系统只保留一个分区继续提供服务,其他分区不可用,直到网络恢复正常。 应用: ZooKeeper, HBase, MongoDB, Redis(集群模式)等。这些系统通常用于需要强一致性的场景,如协调、锁服务、元数据管理等
- AP: 满足可用性和分区容忍性,牺牲一致性。当网络分区发生时,系统保持所有分区都可用,但可能返回过期的数据,直到数据同步完成。 应用: Eureka, Cassandra, CouchDB, DynamoDB, Riak, Redis(哨兵模式)等。这些系统通常用于需要高可用性和可扩展性的场景,如缓存、消息队列、文档存储等
Nacos支持AP+CP, Nacos可以根据配置或者服务节点的状态来识别为AP模式或CP模式,默认是AP模式。如果注册Nacos的client节点注册时ephemeral=true,那么Nacos集群对这个client节点的效果就是AP,采用distro协议实现;而注册Nacos的client节点注册时ephemeral=false,那么Nacos集群对这个client节点的效果就是CP,采用raft协议实现。
远程调用
原本我们只有一个单体项目(黑马商城), 现在由于各业务模块的拆分, 以至于原本直接跨模块注入的方法不能调用
在拆分的时候,我们发现一个问题:就是购物车业务中需要查询商品信息,但商品信息查询的逻辑全部迁移到了item-service服务,导致我们无法查询。
最终结果就是查询到的购物车数据不完整,因此要想解决这个问题,我们就必须改造其中的代码,把原本本地方法调用,改造成跨微服务的远程调用(RPC,即Remote Produce Call)
此时需要变动的代码是这一步:(下面带-的)
1 | private void handleCartItems(List<CartVO> vos) { |
在没有使用微服务之前并没有使用过跨服务调用, 在拆分遇到的第一个问题就是: 需要在一个服务调用另外一个服务的接口
如何进行跨微服务的远程调用呢?
RestTemplate
Spring给我们提供了一个RestTemplate的API,可以方便的实现Http请求的发送。
使用步骤如下:
- 注入RestTemplate到Spring容器
1 |
|
- 发起远程调用
1 | public <T> ResponseEntity<T> exchange( |
构造器注入新体验
某类中注入RestTemplate
1 | private final RestTemplate restTemplate; // final |
然后使用lombok中的注解@RequiredArgsConstructor必需的函数构造器
远程调用改造原代码
1 | private void handleCartItems(List<CartVO> vos) { |
在这个过程中,item-service提供了查询接口,cart-service利用Http请求调用该接口。因此item-service可以称为服务的提供者,而cart-service则称为服务的消费者或服务调用者
小总结
如何拆分?
- 首先要做到高内聚、低耦合
- 从拆分方式来说,有横向拆分和纵向拆分两种。纵向就是按照业务功能模块,横向则是拆分通用性业务,提高复用性
服务拆分之后,不可避免的会出现跨微服务的业务,此时微服务之间就需要进行远程调用。微服务之间的远程调用被称为RPC,即远程过程调用。RPC的实现方式有很多,比如:
- 基于Http协议
- 基于Dubbo协议
案例中使用的是Http方式,这种方式不关心服务提供者的具体技术实现,只要对外暴露Http接口即可,更符合微服务的需要。
Java发送http请求可以使用Spring提供的RestTemplate,使用的基本步骤如下:
- 注册RestTemplate到Spring容器
- 调用RestTemplate的API发送请求,常见方法有:
- getForObject:发送Get请求并返回指定类型对象
- PostForObject:发送Post请求并返回指定类型对象
- put:发送PUT请求
- delete:发送Delete请求
- exchange:发送任意类型请求,返回ResponseEntity
对于刚刚案例的远程调用方式, 固定IP和端口, 访问固定的服务, 那么现在出现问题有: 1)假如固定访问的服务器宕机了怎么办 2)假如使用多服务,那么该怎么去指定访问服务呢 3)如果并发太高,item-service临时多部署了N台实例,cart-service如何知道新实例的地址
Nacos服务注册和发现
注册中心原理
在微服务远程调用的过程中,包括两个角色:
- 服务提供者:提供接口供其它微服务访问,比如
item-service - 服务消费者:调用其它微服务提供的接口,比如
cart-service
在大型微服务项目中,服务提供者的数量会非常多,为了管理这些服务就引入了注册中心的概念。
注册流程如下:
- 服务启动时就会注册自己的服务信息(服务名、IP、端口)到注册中心
- 调用者可以从注册中心订阅想要的服务,获取服务对应的实例列表(1个服务可能多实例部署)
- 调用者自己对实例列表负载均衡,挑选一个实例
- 调用者向该实例发起远程调用
当服务提供者的实例宕机或者启动新实例时,调用者如何得知呢?
- 服务提供者会定期向注册中心发送请求,报告自己的健康状态(心跳请求)
- 当注册中心长时间收不到提供者的心跳时,会认为该实例宕机,将其从服务的实例列表中剔除
- 当服务有新实例启动时,会发送注册服务请求,其信息会被记录在注册中心的服务实例列表
- 当注册中心服务列表变更时,会主动通知微服务,更新本地服务列表
Nacos注册中心配置
Nacos官网 Nacos
开门见山
在Windows本地
存储Nacos数据, 首先我们需要在MySQL中创建表nacos, SQL脚本在
conf目录下找到初始化脚本nacos-mysql.sql, 然后导入即可修改
nacos的application.properties配置文件, 设置数据库连接为MySQL
1 | #*************** Config Module Related Configurations ***************# |
- 单机启动指令:
startup.cmd -m standalone, 或者在startup.cmd文件中set MODE="standalone"
在Docker部署
- 存储Nacos数据, 首先我们需要在MySQL中创建表nacos, SQL脚本在
conf目录下找到初始化脚本nacos-mysql.sql, 然后导入即可 - 创建挂载
conf和logs目录
1 | mkdir -p /idata/nacos/logs/ #新建logs目录 |
- 创建容器
1 | docker run -p 8848:8848 --name nacos -d nacos/nacos-server |
- 启动容器
1 | docker run -d |
-e JVM_XMS=256m : 为jvm启动时分配的内存
-e JVM_XMX=256m : 为jvm运行过程中分配的最大内存
注意事项
需要在防火墙开放相关端口,如果你是云服务器,开放安全组,下面提供相关语句
1 | ## 开放端口8848 9848 9849 |
- 跟在Windows配置一样, 进入Nacos配置
服务注册
接下来,我们把服务注册到Nacos,步骤如下:
- 引入依赖
- 配置Nacos地址
- 重启
添加依赖
在需要服务注册的pom.xml中添加依赖
1 | <!--nacos 服务注册发现--> |
配置Nacos
1 | spring: |
启动服务实例
在IDEA可以启动多个实例, 复制一份启动配置然后在VM Options中配置其他端口即可(在同一台机器上)
然后启动, 登录nacos就可以看到服务上线
服务发现
服务的消费者要去nacos订阅服务,这个过程就是服务发现,步骤如下:
- 引入依赖
- 配置Nacos地址
- 发现并调用服务
服务发现除了要引入nacos依赖以外,由于还需要负载均衡,因此要引入SpringCloud提供的LoadBalancer依赖。
我们在模块中导入依赖:
1 | <!--nacos 服务注册发现--> |
可以发现,这里Nacos的依赖于服务注册时一致,这个依赖中同时包含了服务注册和发现的功能。因为任何一个微服务都可以调用别人,也可以被别人调用,即可以是调用者,也可以是提供者。
因此,等一会儿cart-service模块启动,同样会注册到Nacos
配置Nacos地址
在cart-service的application.yml中添加nacos地址配置:
1 | spring: |
发现并调用服务(负载均衡)
对于发现注册的服务需要在启动类上加注解@EnableDiscoveryClient
1 |
|
接下来,服务调用者cart-service就可以去订阅item-service服务了。不过item-service有多个实例,而真正发起调用时只需要知道一个实例的地址。
因此,服务调用者必须利用负载均衡的算法,从多个实例中挑选一个去访问。常见的负载均衡算法有:
- 随机
- 轮询
- IP的hash
- 最近最少访问
- …
这里我们可以选择最简单的随机负载均衡。
另外,服务发现需要用到一个工具,DiscoveryClient,SpringCloud已经帮我们自动装配,我们可以直接注入使用:
1 | private DiscoveryClient discoveryClient; // 构造器注入 |
那么对于之前固定服务者的的IP操作进行修改, 通过DiscoveryClient发现服务实例列表,然后通过负载均衡算法,选择一个实例去调用
1 | private final DiscoveryClient discoveryClient; // 构造器注入 |
此时在swagger进行测试, 当前测试建立在我们一个模块开启多个服务的情况下, 通过发多次请求, 后台控制台均有日志输出信息, 说明负载均衡起作用了
假如现在有服务挂了(总共服务: 1.ItemApplication 2.ItemApplication2), 2服务挂了, 再次测试发现SpringCloud自动感知到了, 此时请求全部打在服务1上
对于上述负载均衡方案为手写的随机负载均衡,除了该方案还有基于原生的RestTemplate方案,如下:
1 |
|
我们通过原生的RestTemplcate在Spring容器中注册Bean,并且在Bean上面加注解@LoadBalanced来实现负载均衡, 对于当前方案我们需要提供依赖
1 | <!--LoadBalanced--> |
总结
1 | private final DiscoveryClient discoveryClient; // 构造器注入 |
OpenFeign远程调用
在上面的例子,我们利用Nacos实现了服务的治理,利用RestTemplate实现了服务的远程调用。但是远程调用的代码太复杂了(如下code)
1 | // 2.1 根据服务名称获取服务的实例列表 |
有什么方法可以让远程调用像本地方法调用一样简单呢? 你说呢, 看这一小节的标题
下面例子还是以 cart-service中的查询购物车为例
使用
导入依赖
在cart-service服务的pom.xml中引入OpenFeign的依赖和loadBalancer依赖:
1 | <!--openFeign--> |
启用OpenFeign
在cart-service的CartApplication启动类上添加注解,启动OpenFeign功能
1 |
|
编写OpenFeign客户端
在cart-service中,定义一个新的接口,编写Feign客户端:
其中代码如下:
1 | // 服务名 |
这里只需要声明接口,无需实现方法。接口中的几个关键信息:
@FeignClient("item-service"):声明服务名称@GetMapping:声明请求方式@GetMapping("/items"):声明请求路径@RequestParam("ids") Collection<Long> ids:声明请求参数List<ItemDTO>:返回值类型
有了上述信息,OpenFeign就可以利用动态代理帮我们实现这个方法,并且向http://item-service/items发送一个GET请求,携带ids为请求参数,并自动将返回值处理为List<ItemDTO>。
我们只需要直接调用这个方法,即可实现远程调用了
使用FeignClient
基于上面编写的客户端接口
我们在cart-service的com.hmall.cart.service.impl.CartServiceImpl中改造代码,直接调用ItemClient的方法(即老例子)
1 | // private final RestTemplate restTemplate; |
feign替我们完成了服务拉取、负载均衡、发送http请求的所有工作,是不是看起来
而且,这里我们不再需要RestTemplate了,还省去了RestTemplate的注册。
服务消费者
服务消费者的启动类上开启OpenFeign客户端@EnableFeignClients(), 括号里面可选指定扫描注册路径和默认行为指定(当前两处横线 案例可参考当前#OpenFeign章节的#最佳实践 和#日志配置),
服务提供者
服务提供者抽取服务消费者需要调用的方法, 注册至Client, 我们可以定义一个模块为api模块专门用于提取接口暴露, 集中注册便于客户端扫描, 其中在Client接口类通过@FeignClient("xxx-service")指定服务名(当前服务名为服务提供者的应用名)
1 | # 每一个springboot微服务都需要取一个名字 |
每一个服务可以是服务提供者也可以是服务消费者
连接池
Feign底层发起http请求,依赖于其它的框架。其底层支持的http客户端实现包括:
- HttpURLConnection:默认实现,不支持连接池
- Apache HttpClient :支持连接池
- OKHttp:支持连接池
因此我们通常会使用带有连接池的客户端来代替默认的HttpURLConnection。比如,我们使用OK Http
引入依赖
在cart-service的pom.xml中引入依赖:
1 | <!--OK http 的依赖 --> |
开启连接池
在cart-service的application.yml配置文件中开启Feign的连接池功能:
1 | feign: |
然后就开启完成了, 测试是否开启可以通过Debug模式查看
最佳实践
关于重复的编码结果, 我们可以通过
对于api模块抽取, 需要调用api模块中的接口的模块则添加对于该模块的依赖
例:抽取Feign客户端
- 创建一个模块, 专门用来放api的, 导入依赖
1 | <!--openFeign--> |
因为此模块是客户端, 所以 是要导入OpenFeign和负载均衡为基础的
- 在该模块中把之前的
Client移动过来, 因为该接口需要用到ItemDto, 故dto也要移动过来 - 在需要引用(调用)该模块的pom文件中,
导入依赖 , 如果此时运行是不行的, 当前模块没有被扫描到, 没有被Spring管理, 因为此时在另外一个模块了, 不在扫描的路径下了 - 添加扫描
在需要调用的模块的启动类上添加声明即可,两种方式:
- 方式1:声明扫描包:
1 | // 类全路径(抽取的模块) |
- 方式2:声明要用的FeignClient
1 | // 客户端接口 |
日志配置
OpenFeign只会在FeignClient所在包的日志级别为DEBUG时,才会输出日志。而且其日志级别有4级:
- NONE:不记录任何日志信息,这是默认值。
- BASIC:仅记录请求的方法,URL以及响应状态码和执行时间
- HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
- FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
Feign默认的日志级别就是NONE,所以默认我们看不到请求日志。
定义日志级别
在刚刚抽取的client模块下新建一个配置类,定义Feign的日志级别:
1 | import feign.Logger; |
配置
接下来,要让日志级别生效,还需要配置这个类。有两种方式:
- 局部生效:在某个
FeignClient中配置,只对当前FeignClient生效
1 |
- 全局生效:在
@EnableFeignClients中配置,针对所有FeignClient生效。
1 |
一般情况不需要配置日志, 仅仅在有需要的时候在开启即可
Gateway网关路由
网关就是网络的关口。数据在网络间传输,从一个网络传输到另一网络时就需要经过网关来做数据的路由和转发以及数据安全的校验, 其实就是委托
eg: 有人在小区楼下找你, 但是在楼下保安会拦住, 然后只能询问保安, 然后让保安去找你
现在,微服务网关就起到同样的作用。前端请求不能直接访问微服务,而是要请求网关:
- 网关可以做安全控制,也就是登录身份校验,校验通过才放行
- 通过认证后,网关再根据请求判断应该访问哪个微服务,将请求转发过去
网关在注册中心找服务, 负载均衡
SpringCloud Gateway
创建网关模块 gateway
导入依赖
1 | <!--网关--> |
编写启动类
1 |
|
配置路由
在gateway模块中的配置文件中
1 | server: |
详情配置: [Spring Cloud Gateway](Spring Cloud Gateway)
然后所有在网关注册的服务的访问,
路由过滤
对于刚刚案例中的路由配置( 截取一部分 )
1 | spring: |
追踪router可以发现
1 |
|
我们可以发现routes是一个集合, 那么可以定义多个路由项
其中路由的属性如下
1 |
|
四个属性含义如下:
id:路由的唯一标示predicates:路由断言,其实就是匹配条件filters:路由过滤条件,后面讲uri:路由目标地址,lb://代表负载均衡,从注册中心获取目标微服务的实例列表,并且负载均衡选择一个访问。
在当前属性中, 显然最关心的是路由断言(predicates), 其中包括很多语法如下
| 名称 | 说明 | 示例 |
|---|---|---|
| After | 是某个时间点后的请求 | - After=2037-01-20T17:42:47.789-07:00[America/Denver] |
| Before | 是某个时间点之前的请求 | - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] |
| Between | 是某两个时间点之前的请求 | - Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver] |
| Cookie | 请求必须包含某些cookie | - Cookie=chocolate, ch.p |
| Header | 请求必须包含某些header | - Header=X-Request-Id, \d+ |
| Host | 请求必须是访问某个host(域名) | - Host=.somehost.org,.anotherhost.org |
| Method | 请求方式必须是指定方式 | - Method=GET,POST |
| Path | 请求路径必须符合指定规则 | - Path=/red/{segment},/blue/** |
| Query | 请求参数必须包含指定参数 | - Query=name, Jack或者- Query=name |
| RemoteAddr | 请求者的ip必须是指定范围 | - RemoteAddr=192.168.1.1/24 |
| weight | 权重处理 |
网关登录校验
对于单体架构, 我们只需要完成一次用户登录、进行身份校验就可以在所有业务中得到用户信息(ThreadLocal)。在微服务下,每一个服务都是一个单独部署,数据不像单体架构那样共享。
在上一部分我们知道,所有的微服务请求只要在网关中注册然后,请求只需要打在网关上面就可以定向到具体的服务,那么大胆猜想:岂不是可以在网关中做校验,然后把校验数据放请求头里面是不是就完成了身份互通,那么
- 只需要在网关和用户服务保存秘钥
- 只需要在网关开发登录校验功能
由网关下发传递用户信息签发服务,不过,这里存在几个问题:
- 网关路由是配置的,请求转发是Gateway内部代码,我们如何在转发之前做登录校验?
- 网关校验JWT之后,如何将用户信息传递给微服务?
- 微服务之间也会相互调用,这种调用不经过网关,又该如何传递用户信息?
网关过滤器
登录校验必须在请求转发到微服务之前做,否则就失去了意义。而网关的请求转发是Gateway内部代码实现的,要想在请求转发之前做登录校验,就必须了解Gateway内部工作的基本原理。
如图所示,我们只需要将自定义过滤器的执行顺序定义到NettyRoutingFilter之前即可。
网关过滤器链中的过滤器有两种:
GatewayFilter:路由过滤器,作用范围比较灵活,可以是任意指定的路由Route.GlobalFilter:全局过滤器,作用范围是所有路由,不可配置。
注意:过滤器链之外还有一种过滤器,HttpHeadersFilter,用来处理传递到下游微服务的请求头。例如org.springframework.cloud.gateway.filter.headers.XForwardedHeadersFilter可以传递代理请求原本的host头到下游微服务。
其实GatewayFilter和GlobalFilter这两种过滤器的方法签名完全一致。
1 | /** |
Gateway中内置了很多的网关过滤器, 详情可以参考官方文档Spring Cloud Gateway
单服务应用:
1 | spring: |
例如我此时给cart-service路由服务添加了请求过滤器,访问cart服务则在请求头里面会新增Key:key Value:value
多服务应用:
1 | spring: |
自定义过滤器
自定义GatewayFilter
前置: 如果有传参数,定义执行顺序,范围等则用此项
自定义GatewayFilter不是直接实现GatewayFilter,而是实现AbstractGatewayFilterFactory。最简单的方式是这样的:
1 |
|
当前自定义类名的后缀必须为:
GatewayFilterFactory
众所周知SpringBoot约定大于配置,当我们这样命名的时候,在yaml中配置可以是这样的
1 | spring: |
另外,这种过滤器还可以支持动态配置参数,不过实现起来比较复杂,示例:
1 |
|
然后在yaml文件中使用:
1 | spring: |
上面这种配置方式参数必须严格按照shortcutFieldOrder()方法的返回参数名顺序来赋值。
还有一种用法,无需按照这个顺序,就是手动指定参数名:
1 | spring: |
自定义GlobalFilter
简单的过滤器
自定义GlobalFilter则简单很多,直接实现GlobalFilter即可,而且也无法设置动态参数:
1 |
|
Actuator监控
官网文档:Spring Cloud Gateway
导入依赖
1 | <dependency> |
配置打开的端点
1 | management: # 通过 actuator暴露此服务的管理端口 |
以下所有端点都挂在/actuator/gateway/ 下面
测试
- 可以访问 你的服务+/actuator/gateway/routefilters, 进行查看所有的过滤器工厂
- /actuator/gateway/routes: 展示所有的路由列表
自定义谓词工厂Predicates
众所周知 SpringCloud Gateway有很多内置的谓词工厂, 一般用的最多的是通过路径谓词工厂判断。
分析PathRoutePredicateFactory谓词工厂
要实现自定义谓词工厂,我们先分析PathRoutePredicateFactory谓词工厂.
1 | // 1.继承AbstractRoutePredicateFactory<泛型自己的内部配置类.Config> |
仅保留主框架结构
对于工厂模式: 该谓词工厂模式通过继承了一个抽象工厂, 实现重写apply方法
1 | // RoutePredicateFactory为AbstractRoutePredicateFactory继承的接口 |
所以最核心的就是 内部配置类和apply方法
其中内部配置类中 patterns是一个List集合, 模式可以有多个 .
读取到配置类, 生成谓词语句, 然后遍历解析判断
小结论
那么到这儿可以得出一个结论, 因为是一个一个的遍历解析判断, 那么就一定存在执行的先后顺序问题, 所以
自定义谓词工厂
例如我需要自定义一个在时间区间的(需要传入两个参数)
- 在网关模块
1 | /** |
- 配置好在启动的时候会出现
1 | 2023-12-20 21:28:41.488 INFO 6268 --- [ main] o.s.c.g.r.RouteDefinitionRouteLocator : Loaded RoutePredicateFactory [TimeBetween] |
那么就证明已经被托管了
- Yaml
1 | spring: |
然后就可以获取这两个参数了, 匹配到则会进行到我们自定义的谓词判断
配置管理
到此完成了在微服务相关的问题:
- 远程调用
- 服务注册发现
- 请求路由网关、负载均衡
- 登录信息拦截传递(上章节未完成)
到这儿可以发现,配置文件全是写死的,非常不灵活
- 如果修改必须重新启动微服务
- 对于很多重复的配置显然可以抽取出来
这些问题都可以通过统一的配置管理器服务解决。而Nacos不仅仅具备注册中心功能,也具备配置管理的功能:
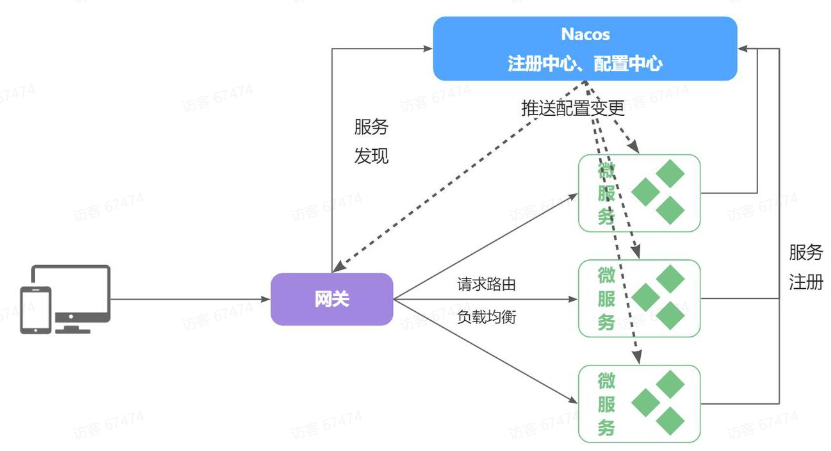
微服务共享的配置可以统一交给Nacos保存和管理,在Nacos控制台修改配置后,Nacos会将配置变更推送给相关的微服务,并且无需重启即可生效,实现配置热更新。
网关的路由同样是配置,因此同样可以基于这个功能实现动态路由功能,无需重启网关即可修改路由配置。
到了此处,我们应该了解配置中心的架构图了
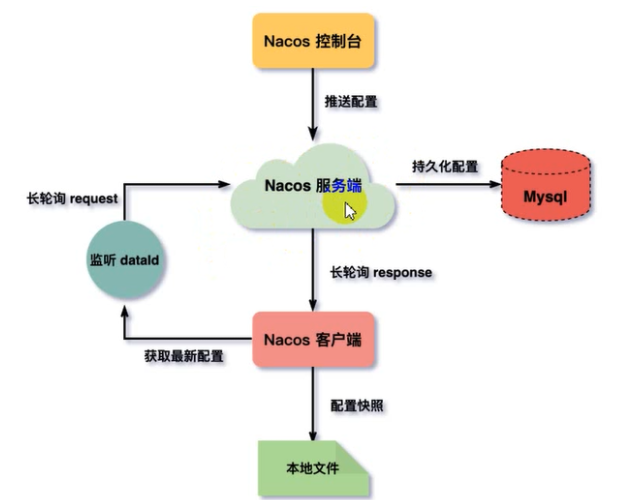
不难看出来,该处使用的设计模式为观察者模式,通过监听配置的变化,通知客户端修改配置,对于Nacos的持久化信息处理采用移入MySQL的方案
抽取配置部署在Nacos(入门)
对于抽取配置我们必须知道: 配置文件也是有执行顺序的
入门案例:了解结构
需求点:在微服务启动时就要访问nacos配置中心
对于需要满足此需求,我们需要了解在nacos中如何管理配置文件。
启动nacos,为你的项目起一个命名空间(可选),在配置列表选择一个命名空间,在命名空间中添加配置文件,此时可以看到一个名为Data Id的字段,对于该字段笔者建议取例如该:cloud-user-dev.yml, 对于该配置命名的解释: ${prefix}-${spring.profiles.active}.${file-extension}
易知: prefix为前缀名, spring.profiles.active为配置生效的环境, file-extension为文件后缀
到这可能会产生一个疑问:为什么需要这样取? 因为这样取名一目了然且SpringBoot中的nacos配置文件就是读取这样的结构(如下图)
1 | spring: |
在读取后就会自动拼接。
在这里的时候会想:到底是什么文件才能让他在启动时就可以访问,在之前我们知道配置文件有俩种方案(忽略不同后缀配置)
- 通过
application.yml的配置文件配置 - 在启动时通过命令行例如
-Dserver.port=8080: 此项必须建立在启动类传入了args的情况
阅读到这 他们俩的加载顺序凭经验就可以知道: 命令行 > application.yml
解析bootstrap.yml
application.yml与bootstrap.yml的区别:
- 加载顺序
bootstrap.yml先加载,application.yml后加载。bootstrap.yml用于应用程序上下文的引导阶段,由父Spring ApplicationContext加载。
- 配置区别
bootstrap.yml用来程序引导时执行,应用于更加早期配置信息读取,可以理解成系统级别的一些参数配置,这些参数一般是不会变动的。一旦bootStrap.yml被加载,则内容不会被覆盖。application.yml可以用来定义应用级别的,应用程序特有配置信息,可以用来配置后续各个模块中需使用的公共参数等。
- 属性覆盖问题
启动上下文时,Spring Cloud会创建一个Bootstrap Context,作为Spring应用的Application Context的父上下文。初始化的时候,Bootstrap Context负责从外部源加载配置属性并解析配置。这两个上下文共享一个从外部获取的Environment。Bootstrap属性有高优先级,默认情况下,它们不会被本地配置覆盖。也就是说如果加载的application.yml的内容标签与bootstrap的标签一致,application也不会覆盖bootstrap,而application.yml里面的内容可以动态替换。
- 如何使用
在springcloud2020以后禁用了bootstrap.yml,如要重新打开,则需导入依赖
1 | <dependency> |
如何简单的使用
- 导入依赖
1 | <!--开启对bootstrap.yml支持--> |
- 利用bootstrap.yml做启动配置(图例再现)
1 | spring: |
在上述的配置配置完成之后, 可以在nacos尝试发布(示例配置)
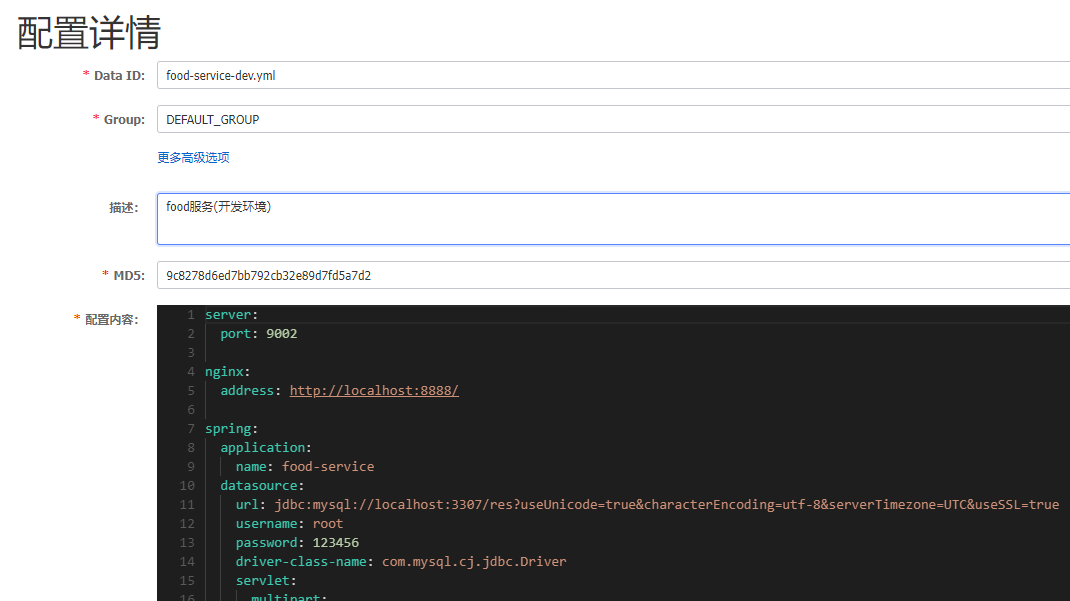
此时配置完成(笼统的配置), 在项目中的配置(application.yml)就可以试着注释掉了, 还是和原来的启动结果一样
探索点: 此时我们可以试着把端口修改一下然后重启看看会发生什么奇效
动态刷新
到这的时候, 我们在上一章节的需求似乎就完成了, 虽然抽取了启动的时候的配置文件, 这样似乎比之前确实好很多了, 可以动态修改端口这些
我们还需要动态刷新其他的属性其他的值呢?
我们可以使用注解@RefreshScope去获取到动态刷新的值 样例如下:
1 |
|
我们只需要在nacos的当前配置文件中修改my.pattern.dateFormatString的值就可以动态修改时间的格式了(yyyy-MM-dd HH:mm:ss -> yyyy年MM月dd日 HH:mm:ss)
- 加在类上可以自动感知属性的变化
- 加在方法上可以感知方法里面的值变化
当前描述的值为被绑定过的值
那么底层肯定是结合了 SpringBoot中的actuator的支持, 并且开放了 refreshScope端点的支持, 那么才能动态感知, 其实就是nacos服务器向项目的端点(refreshScope)发了一个请求 (POST /actuator/refresh)
配置文件版本控制
在nacos的配置管理中有一个配置回滚项(名为:历史版本)
配置共享
我们可以把微服务共享的配置抽取到Nacos中统一管理,这样就不需要每个微服务都重复配置了。分为两步:
- 在Nacos中添加共享配置
- 微服务拉取配置
如何添加共享配置呢? 数据库当然可以使用同一个, Redis也可以 …
那么把他们的配置给抽取出来 例如: mysql8-local.yml和redis-local.yml
在nacos配置中创建该示例
抽取前面笼统的配置(mysql和redis的配置等), 当然也可以抽取其他的例如日志
例如抽取在nacos的redis配置
1 | spring: |
抽取完成之后我们需要在bootstrap.yml中增加项(前面带+, 如需缩减则+变空格)
1 | spring: |
上述俩项配置后, 需在前面的笼统配置中删除重复项
大功告成 !
小任务
需求点:结合nacos配置中心完成druid的数据库的切换
自己思考
样例代码
1 | //将原来的springboot的自动IOC DruidDatasource方案改为 手工编程 |
但是此时会发现有坑, druid数据源在设置的时候有检查
1 | // 如果被设置过则抛出异常 |
也就是说按道理来说是不能修改的
实际上: nacos在修改此项之后会创建一个新的DataSource导致这个不生效 ( )
Sentinel服务哨兵
章节前言
在了解Sentinel之前可以了解:
- 什么是服务雪崩?服务雪崩发生时的各阶段及直接原因?
- 应对服务雪崩的解决方案?(从硬件和软件方面分别考量)
- 什么是限流?
- 什么是服务熔断? 解决服务熔断的通过模型为断路器模式,它是什么原理?
- 什么是服务降级?
- 限流算法中的令牌桶算法与漏桶算法的原理及区别?
- 什么是职责链设计模式?请写一个简单的案例?
- 什么是热点数据?如何解决热点数据的访问问题?常见的策略有LRU,LFU, FIFO, 请掌握每种策略的原理及简单实现.
Jmiter简单使用
在使用Sentinel之前需要有一个*压测工具*(JMeter - Download)来支撑我们的测试, 通过测试评估系统响应、吞吐量等,根据评估结果优化系统。
运行: 下载账户在bin目录找到jmeter.bat
- 中文设置: 编辑将
set JMETER_LANGUAGE=-Duser.language="en" -Duser.region="EN"设置为set JMETER_LANGUAGE=-Duser.language="zh" -Duser.region="CN" - 双击该脚本即可运行
编写压测案例:
在测试计划中添加线程组, 在线程组里设置线程数和循环次数以及Ramp-Up持续时间
在线程组添加Http请求, 设置请求名称、协议、IP、端口、请求、路径
对于此项可以添加随机数, 工具->函数助手对话框-> Random范围(可选其他函数) -> 生成
在一个线程组层级可以设置汇总报告以及结果树用于查看压测数据
Sentinel概念
服务雪崩
简单来说服务雪崩就是,一个服务失败,导致整条链路的服务都失败的情形
服务雪崩的三个阶段以及原因:
- 阶段一: 服务不可用
原因可能如下: 缓存击穿, 硬件故障, 用户大量请求, 程序Bug
- 阶段二: 调用端重试加大流量
原因可能如下: 用户重试, 代码逻辑重试
- 阶段三: 服务调用者不可用
原因可能如下: 同步等待造成的资源耗尽
对于以上的三个阶段可以产生有解决方案如下:
- 应用型扩容: 加机器, 升级硬件
- 流控: 限流(信号量), 关闭重试, 超时处理
- 缓存: 缓存预加载
- 服务降级: 服务接口拒绝服务 , 页面拒绝服务, 延迟持久化, 随机拒绝服务
- 服务熔断
如何进行限流, 服务熔断?
限流: 提前对各个服务类型的请求设置理想高的QPS阈值, 若高于此阈值则直接对于请求直接返回
服务熔断: 当下游的服务因为某种原因突然变得不可用或响应过慢,上游服务为了保证自己整体服务的可用性,不再继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用, 一句话说就是先保自己的服务
服务熔断
对于断路器模式的状态图大致如下:

在最开始是处于Closed状态, 一旦请求达到设定阈值则转为Open状态, 此时会有一个重试时间(reset timeout: 其实是重试时间计算器), 如果到达了设定的重试时间则转为半开状态(Half-Open),指部分请求可以请求到后端, 一旦检测通过则到Closed状态(恢复服务)
关于熔断详情官方文档 熔断降级
服务降级
对于服务降级有两种场景:
- 当下游的服务因为某种原因响应过慢,下游服务主动停掉一些不太重要的业务,释放出服务器资源,增加响应速度
- 当下游的服务因为某种原因不可用,上游主动调用本地的一些降级逻辑,避免卡顿,迅速返回给用户
当然服务熔断可视为降级方式的一种
在实际的项目中,也可采用以下的方式来完成降级工作
- 梳理出核心业务流程和非核心业务流程。然后在非核心业务流程上加上开关,一旦发现系统扛不住,关掉开关,结束这些次要流程
- 一个微服务下肯定有很多功能,那自己区分出主要功能和次要功能。然后次要功能加上开关,需要降级的时候,把次要功能关闭
- 降低一致性要求,即将核心业务流程的同步改异步,将强一致性改最终一致性
sentinel是以流量为切入点,从流量控制熔断降级,系统负载保护等多维度保护服务的稳定性
特点
- 多种限流算法:包括令牌桶、漏桶等,可以根据业务场景选择合适的算法。
- 多种限流维度:包括QPS、并发线程数、异常比例等,可以根据不同的维度来进行限流。
- 多种应用场景:支持Dubbo、Spring Cloud、gRPC等多种RPC框架的服务发现和调用。
- 动态规则源:支持多种数据源,如Nacos、Zookeeper、Apollo等,可以动态推送和更新规则。
- 实时监控:提供实时的监控和统计功能,可以查看服务的运行状态和指标
Sentinel的使用: 分为核心库(java Client)和控制台(Web Dasboard)
执行原理
采用职责链设计模式: 该设计模式是sentinel的核心骨架, 它将不同是slot按照顺序组成职责链,, 从而将不同的功能(例如: 限流、降级、系统保护)组合在一起
对于sentinel职责链实践可以跳转阿里Sentinel核心源码解析-责任链模式最佳实践 - 知乎 (zhihu.com)
Sentinel使用与配置
Dashboard
安装Dashboard控制台,下载sentinel-dashboard.jar文件直达链接
下载好之后在文件目录编写处理脚本 例如:start.bat内容如下
1 | java -jar ./sentinel-dashboard-1.8.0.jar --server.port=9999 |
其实就是一个运行jar包的脚本然后设置了端口, 这样设置了便于以后运行
启动jar包后打开网页http://localhost:9999/#/login
通过了解配置文件可以得知账号密码均为: sentinel
详情参考官方文档控制台 · alibaba/Sentinel Wiki (github.com)
微服务整合
依赖及分析
在需要整合的服务中导入依赖
1 | <!-- sentinel 客户端依赖 --> |
对于本案例不再使用硬编码进行一一设置, 如需了解硬编码模式见quick-start | Sentinel
在默认在加了starter依赖、配置完配置文件后,在controller中的接口都会监控,所有的 URL 就自动成为 Sentinel 中的埋点资源。
在官方文档中描述:一般推荐将 @SentinelResource 注解加到服务实现上,而在 Web 层直接使用 Spring Cloud Alibaba 自带的 Web 埋点适配。官方文档
对于Service层
1 |
|
对于了解且使用过硬编码的配置, 可以知道需要导入如下依赖
1 | <!-- Sentinel 核心依赖--> |
对于此第二个依赖:
simple-http:它是一个简版的http服务器,用于与dashboard通讯
它是一种提供HTTP端点的通信模块,用于接收来自Dashboard的控制指令。它是sentinel-transport模块的一个子模块,使用NIO实现了一个简单的HTTP服务器。它的作用是让Sentinel Client能够与Dashboard进行远程通信,实现规则管理和推送、数据上报和监控等功能。
再对sentinel-starter进行分析: 它还导入了aspectj切面, 众所周知我们需要对资源进行统计(QPS)当然是要在请求执行前啦, 那不就是切面前置增强吗
其中还包括一些其他依赖如负载均衡、熔断、远程调用等, 就不一一列出了
Yaml配置
使用了Nacos后, 我们的基础配置应该是放在了Nacos中了, 此时就不需要再放在项目的application.yml了, 我们在Nacos中对应的配置文件处添加
1 | spring: |
在进行到此处, starter和配置文件、 Dashboard都准备好了, 我们可以结合Jmiter进行低QPS(太多了会卡死)的简单压测,查看Sentinel Dashboard的实时监控是否起作用
Sentinel的监控数据是哪来的
Sentinel是基于SpringBoot开发的, SpringBoot提供了一套对外的actuator监控端点,很显然Sentinel就是对暴露端点的数据进行监控然后获得的数据
我们需要了解Sentinel监控的端口可以访问接口http://localhost:8719/api :8719为yml中配置的监听端口
其他配置详情见官方文档(访问上面描述的api接口可以拿取一些url进行二次开发)
Sentinel服务流控
服务流控模式
一: 直接失败
限制QPS或者进程数:
QPS:限制单位时间的请求接口次数限制
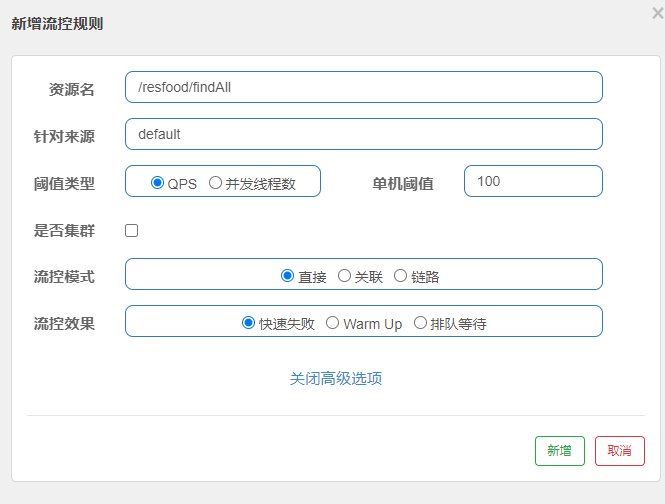
效果图如下 (Sentinel实时监控)
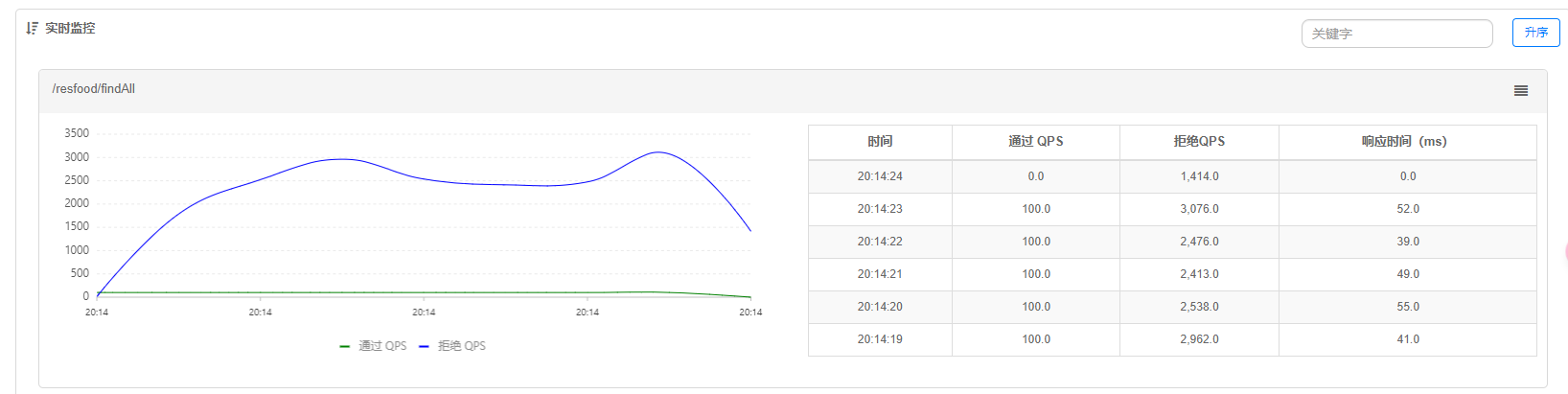
我们可以清晰的看到/resfood/findAll接口的QPS被限制在了100, 其他的都被拒绝了
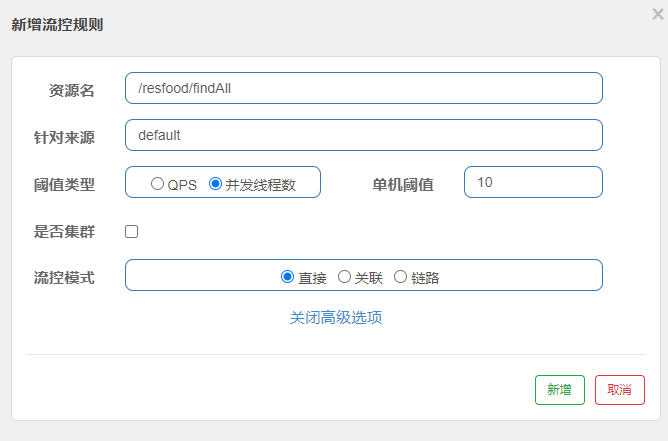
限制进程数:单位时间内,请求并发数限制,这里处理的并发请求是指tomcat中开启多少个线程来处理请求。
在Tomcat中默认线程池数为10, 如需修改我们可以在配置文件中修改
2
3
4
5
6
7
port: 9000 # 此服务的端口(注意各微服务的端口要区分)
tomcat: # 配置tomcat相关参数
accept-count: 100 # 等待队列长度,默认100。
max-threads: 20 # 最大工作线程数,默认200。
min-spare-threads: 5 # 最小工作空闲线程数,默认10。
max-connections: 100 # 最大连接数,默认为10000
并发线程数控制界面如下
二: 关联失败
当关联的资源达到阈值时,就限流自己
需求场景: 在 resfood服务中, 在/resfood/findById/{fid}访问量暴涨的情况下,我们确定保护它的服务 而快速失败 /resfood/findAll, 即在根据id查找商品的访问量暴涨下我们需要保护它而它关联的查找全部服务则需要失败
应用场景: 订单服务关联第三方支付接口,当支付接口访问过多的时候导致快瘫痪时,那么就限制我们的下单服务(限流)
三: 链路流控
只记录指定链路上的流量(指定资源从入口资源进来的流量,如果达到阈值,就可以限流)[api级别的针对来源]
对于需要使用链路流控, 需要配置 web-context-unify: false
1 | spring: |
为了达到链路的效果, 模拟服务结构如下
ServiceA ,ServiceB各自都依赖于getInfo
当前示例,在Sentinel控制台会显示依赖树形状结构
两个节点都依赖于父节点
简略示例代码
- getInfo()
1 |
|
- ServiceA/B
1 |
|
两个服务对getInfo产生依赖, 如需限流一个服务, 则需对资源getInfo进行链路限流, 在入口资源选项则填入需要限流的服务 例如需要对ServiceA限流以保证ServiceB的平稳运行则在入口资源填入 /resorder/serviceA: 当前为限制ResorderController中接口为serviceA的请求,流控效果根据需要自行选择。
根据上面的案例则可以 实现优先某服务、接口的操作
流控效果
- 快速失败:直接失败
- Warm Up: 预热, 即请求 QPS 从 threshold / 3 开始,经预热时长逐渐升至设定的 QPS 阈值threshold
效果示例如下: (模拟环境如下: Sentinel Dashboard控制: 接口在Sentinel流控下设置QPS阈值25,流控模式为直接流控, 流控效果为Warm Up, 预热时长 3s ** ,压测模拟端: 线程数400个**, Ramp-Up: 5秒, 循环一次)
| 时间 | 通过QPS | 拒绝QPS | 响应时间(ms) |
|---|---|---|---|
| 20:48:07 | 25.0 | 51.0 | 3.0 |
| 20:48:06 | 25.0 | 51.0 | 3.0 |
| 20:48:05 | 18.0 | 59.0 | 3.0 |
| 20:48:04 | 12.0 | 65.0 | 3.0 |
| 20:48:03 | 9.0 | 67.0 | 3.0 |
| 20:48:02 | 8/0 | 2.0 | 3.0 |
可以看出来, 处于预热模式下, 随着时间的推移, QPS逐渐达到阈值然后一直保持最大值, 直到所有请求全部处理完成
应用: 秒杀系统在开启的瞬间,会有很多流量上来,很有可能把系统打死,预热方式就是把为了保护系统,可慢慢的把流量放进来,慢慢的把阀值增长到设置的阀值
- 排队等待

匀速排队,让请求以均匀的速度通过,阀值类型必须设成QPS,否则无效。对应的是漏桶算法
关于排队等待详情见官方文档 流量控制 匀速排队模式
Sentinel熔断降级
官方介绍: 对不稳定的弱依赖服务调用进行熔断降级,暂时切断不稳定调用,避免局部不稳定因素导致整体的雪崩。熔断降级是一个保护自身的手段。熔断降级 · alibaba/Sentinel Wiki
三种策略
慢调用比例 (SLOW_REQUEST_RATIO)
选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断。
慢调用模拟
jmiter: 线程:100, Ramp-Up:5, 循环:1
熔断规则: 资源名; 对当前接口进行绑定, 熔断策略: 慢调用比例, 最大RT: 200(毫秒) [当前设置项为评估接口慢的标准,我们设置了睡眠1000ms肯定是大于该标准的,故会被评估成慢 ], 比例阈值: 0.3 (30%), 熔断时长: 2(秒) [断开时长,不处理的时长], 最小请求数: 5[进行该操作需要的最小请求数], 统计时长:
1000(毫秒)[统计1000毫秒内的慢调用接口]
1 |
|
测试结果: 基于我们设定的测试环境下, 在第一批请求打过去之后必定会熔断, 熔断两秒后, 由于我们设定的是五秒持续发请求, 则两秒之后会打一个请求过来测试是否通路, 如果能则Closed通路
异常比例 (ERROR_RATIO)
当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。
异常比例模拟
1 |
|
异常数 (ERROR_COUNT)
当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
注意异常降级仅针对业务异常,对 Sentinel 限流降级本身的异常(
BlockException)不生效。为了统计异常比例或异常数,需要通过Tracer.trace(ex)记录业务异常
1 |
|
代码中: 异常数40%
jmiter: 线程:100, Ramp-Up:5, 循环:1
熔断规则: 资源名; 对当前接口进行绑定, 熔断策略: 异常数, 异常数: 6, 熔断时长: 2(秒) [断开时长,不处理的时长], 最小请求数: 5[进行该操作需要的最小请求数]
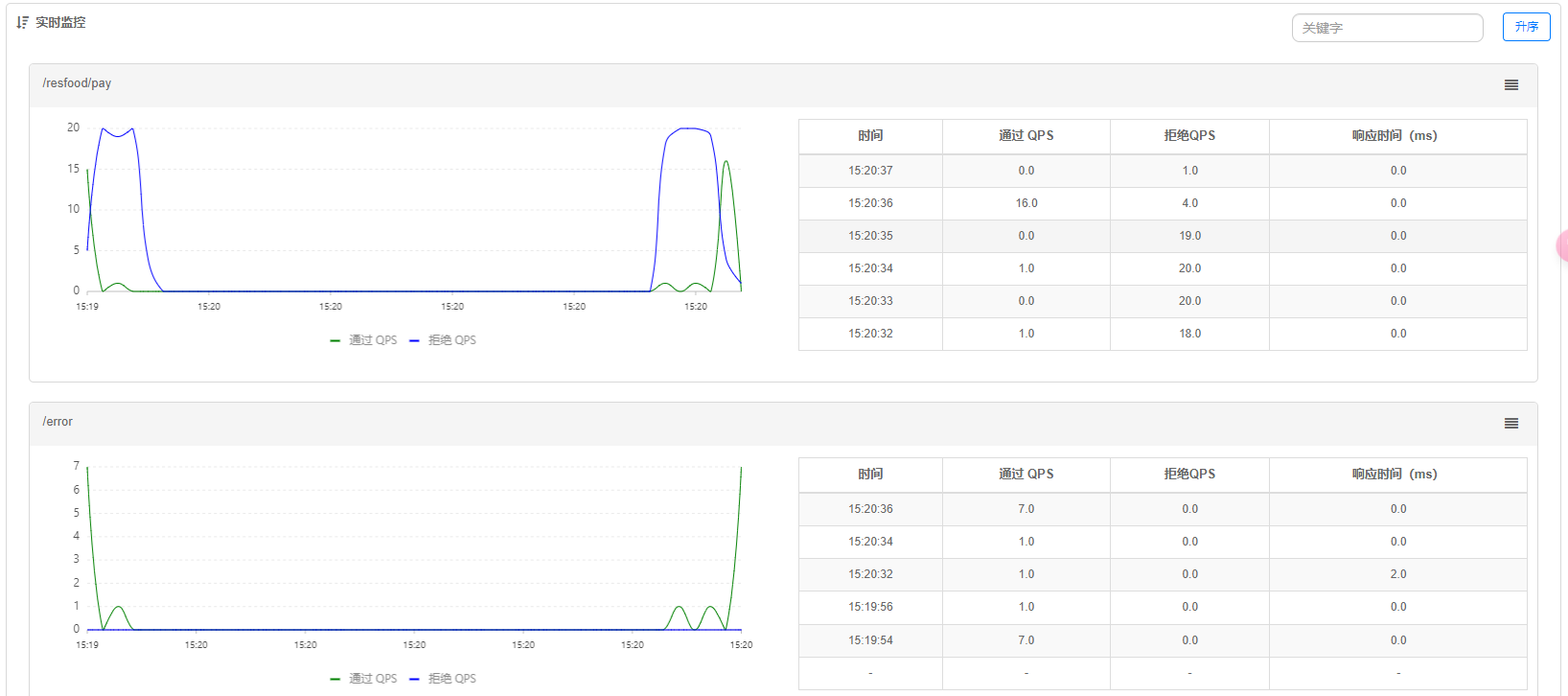
对于当前模拟结过的监控图可以看出, 在右侧的15.20处[即15:20:32-15:20:37], 对于15:20:34处的一个QPS则为熔断后的点测是否可通,可通则Closed通路,对于15:20:36则为通路后的请求,然后又熔断。当前模拟图,在开始请求后异常数就达到了熔断标准。
热点参数限流
案例与介绍
何为热点?热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 Top K 数据,并对其访问进行限制。比如:
- 商品 ID 为参数,统计一段时间内最常购买的商品 ID 并进行限制
- 用户 ID 为参数,针对一段时间内频繁访问的用户 ID 进行限制
热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。
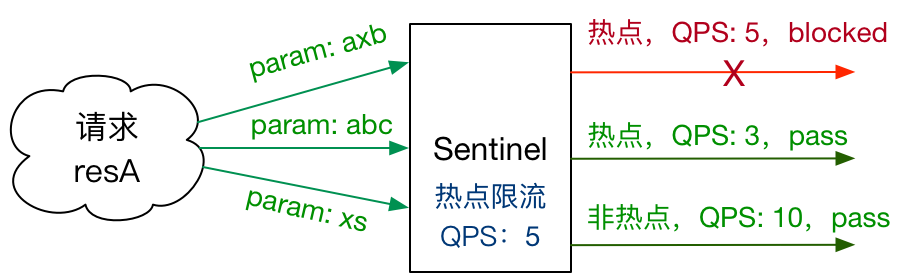
Sentinel 利用 LRU 策略统计最近最常访问的热点参数,结合令牌桶算法来进行参数级别的流控。热点参数限流支持集群模式。
官方文档 热点参数限流 · alibaba/Sentinel Wiki
使用方法:
在需要限流的资源上面增加注解@Sentinel(Xxx), 然后在客户端进行可视化配置限流策略即可
例如我们需要对分页数据进行热点限流, 因为第一页分页往往访问量大 示例如下
1 |
|
配置好注解之后, 我们在Sentinel Dashboard导航栏选择热点规则, 点击新增热点规则, 资源名填入在服务中设置的Key, 参数索引顺序为方法形参顺序(从0开始), 单机阈值访问超过阈值则开启热点限流控制,
统计窗口时长在该时长内。
当前测试环境如下:
客户端: 参数索引: 0 [第0个参数为分页参数], 单机阈值: 5 [在统计窗口时长内有5个请求则进行限流], 统计窗口时长: 1(秒), 对于参数索引可以进行额外配置: 当前我们配置参数类型为Int, 参数值为1(第一页), 限流阈值 10(设置了该项, 单机阈值则失效)
此时发送请求, 对于第一页的数据进行访问, 在一秒钟内开启100个线程访问一次, 最后仅可以访问10(限流阈值)个, 其他的都被限流
热点规则名词了解
LRU 策略
LRU策略是一种缓存淘汰策略,它的全称是Least Recently Used,即最近最少使用。LRU策略的基本思想是:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小,那么就可以将其淘汰。LRU算法的实现方式有很多种,比如可以使用链表、哈希表等数据结构
令牌桶算法
令牌桶算法是一种流量控制算法,它的基本思想是:系统以恒定的速率往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。令牌桶算法的实现方式有很多种,比如可以使用阻塞队列、定时器等方式
黑白名单控制/授权
官方文档 黑白名单控制 · alibaba/Sentinel Wiki (github.com)
需要根据调用来源来判断该次请求是否允许放行,这时候可以使用 Sentinel 的来源访问控制(黑白名单控制)的功能
原理: 来源访问控制根据资源的请求来源(origin)限制资源是否通过,若配置白名单则只有请求来源位于白名单内时才可通过;若配置黑名单则请求来源位于黑名单时不通过,其余的请求通过
其实就是拦截请求头或者其他资源
Sentinel客户端授权
打开Sentinel客户端, 在左侧导航栏选择授权规则, 对指定服务新增授权规则, 示例如下图
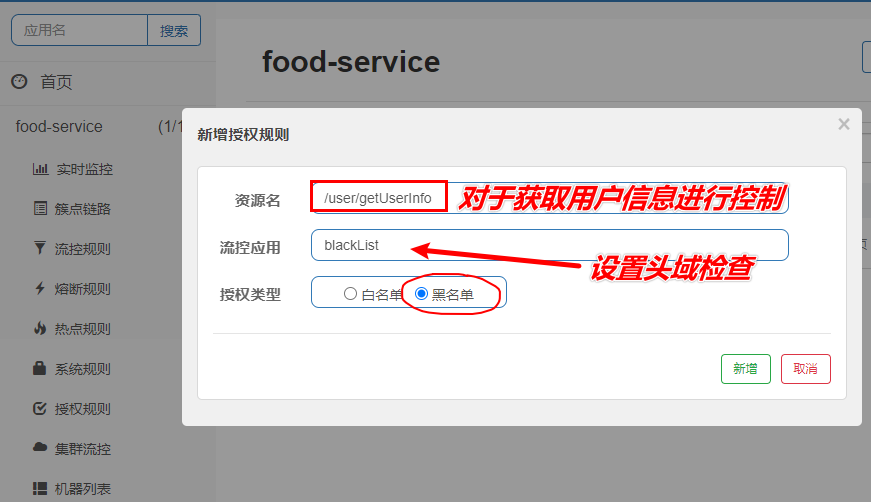
图例中, 我们对资源名为/user/getUserInfo进行规则限制, 设置流控应用为blackList, 授权类型为黑名单. 那么意味着如果Origin中包含blackList则会被进行限制(因为此时是黑名单授权)
如何进行测试呢: 使用jmiter对该接口资源进行访问, 在相对应的资源右键 -> 添加 -> 前置处理器 -> HTTP信息头管理器 -> 在Origin添加value为blackList, 进行并发测试可以清晰的看见所有带此头的请求均被拦截, 在取样结果(结果树)可以看到 : Blocked by Sentinel (flow limiting): Sentinel流控阻止限制.
若调整选项为白名单则包含此头信息的才可以访问该资源
编码授权示例
在服务提供方(FoodService)
- 添加依赖
1 | <!-- sentinel依赖 --> |
- 配置Sentinel服务器
1 | spring: |
- 添加解析器
1 |
|
在服务调用方(OrderService)
- 利用拦截器在openfeign发出请求时统一加入origin信息(此方案不可用,在发送时会添加,但在接收的时候就没有了)
虽然标题说不可用, 不可用的条件是, 我们设置头的key为Origin与其原本的冲突了, 只需要改其他名字就可以了, 例如当前已经修改成source就可以, 在后来只需要拦截source即可
1 | /** |
笔者查阅资料得知还可以在使用SpringMVC注解内添加头域信息, 例
1 | // 不能用Origin,关键字会与原来的字段冲突 |
系统自适应限流
系统自适应限流 · alibaba/Sentinel Wiki
Sentinel 系统自适应过载保护从整体维度对应用入口流量进行控制,结合应用的 Load、CPU 使用率、总体平均 RT、入口 QPS 和并发线程数等几个维度的监控指标,通过自适应的流控策略,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
在Sentinel客户端选择系统规则
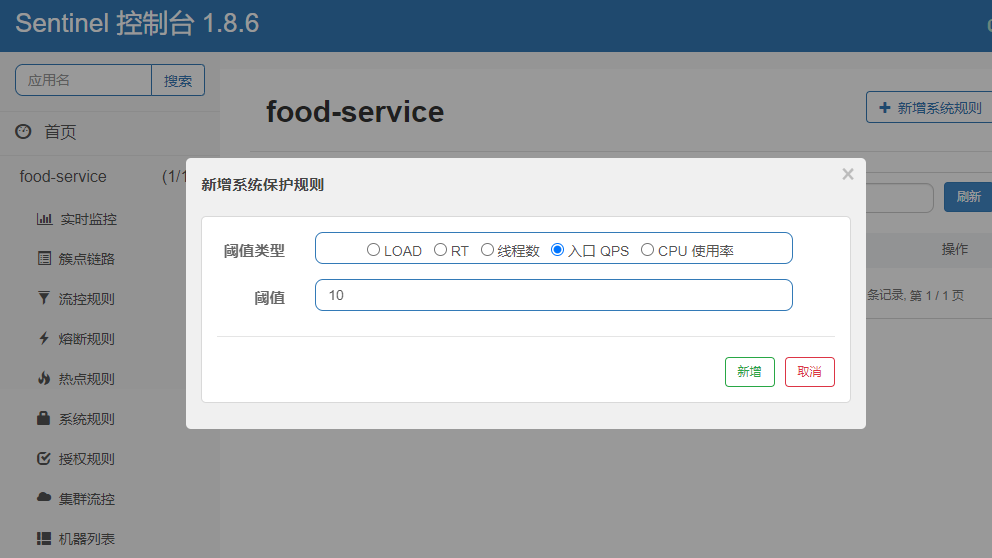
在此案例中我们选择入口QPS为10进行测试, Jmiter测试环境: 60个线程 持续2秒 重复一次(即一秒30QPS)
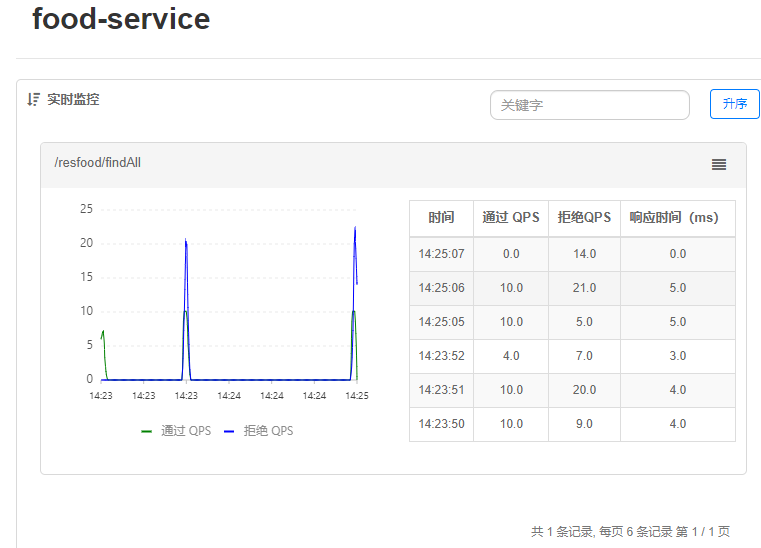
如图超过阈值,则最多只能通过10QPS, 超过该阈值的全部被拒绝
业务异常的回调处理
如果监控的资源出现了业务异常(例如: controller执行调用业务层出现异常,不处理则会抛出500异常)
- 需求: 如果流控规则起作用了,默认情况下,sentinel以 http响应码 4xx形式回送一条 信息, 而不是默认返回的500.
本节下列所述均为在注解
@SentinelResource处理, 例如@SentinelResource(value = "a-service")
blockHandler/blockHandlerClass
blockHandler 用于处理被 Sentinel 阻止的请求,例如当请求超过限流阈值时,Sentinel 会自动阻止该请求,并调用指定的 blockHandler 方法进行处理 , 这样可以将流控这种异常信息转为业务要处理的消息格式.
通过阅读源码注解注释
1 | /** |
可知: 自定义回调处理方法应该与加注解需要处理的资源在同一个类下, blockHandler中指明的方法必须为静态的
代码编写
我们通过设置之后, 选择food-service服务, findByPage接口为例
1 | // 此方法中的参数是由Sentinel在运行时以 DI的方式注入的 |
当前我们设置的是: 如果findByPage接口出现异常, 则会调用blockHandlerMethod方法(即在上面声明的), 声明的方法为: 如果发生了异常, 我们将构造一个返回结果集 code=200, body=””, msg=info
info: 则为我们构造的信息返回
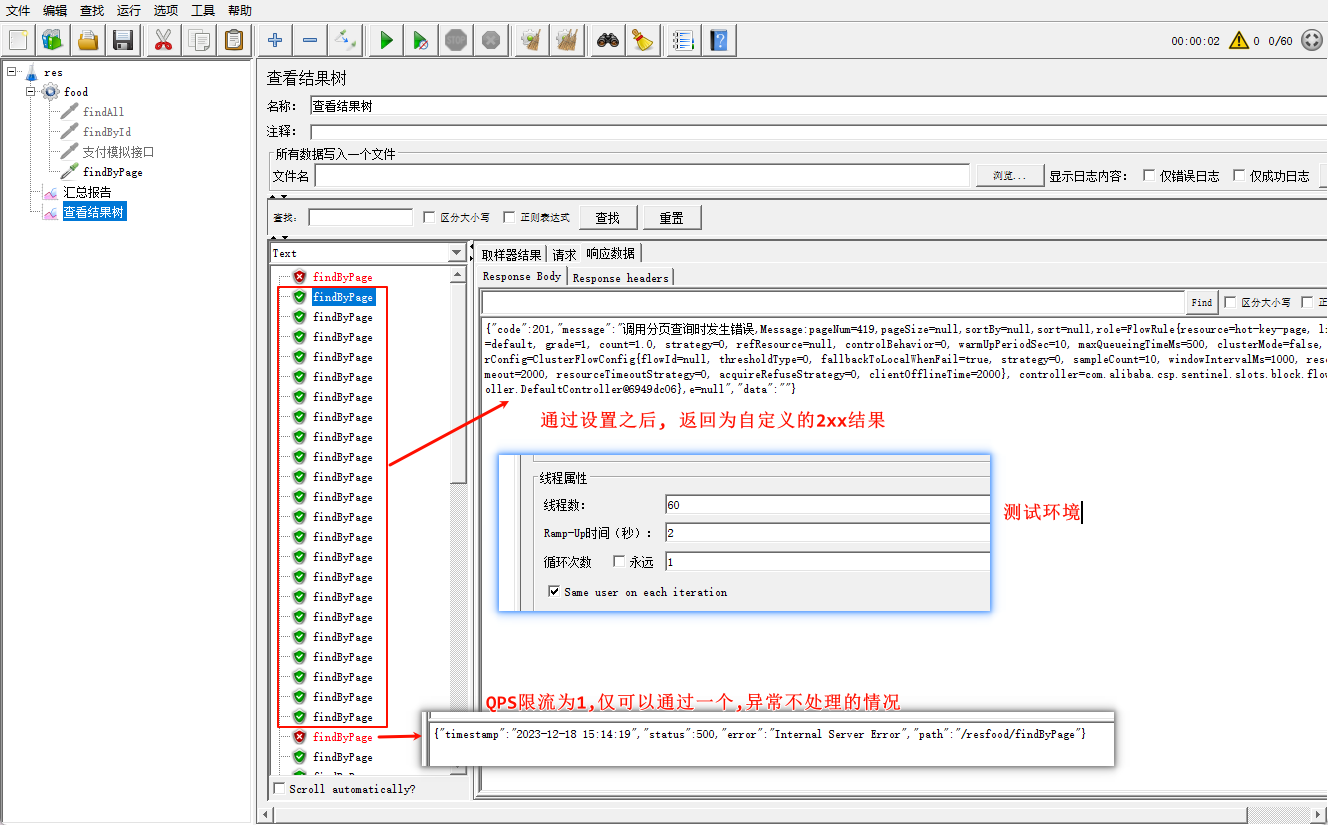
客户端设置流控
(Sentinel Dashboard) 我们在簇点链路 选择流控, 资源为hot-key-page(设置的资源名), QPS设置1 其他高级设置默认即可
测试结果
假如没有设置该项, 那么在Jmiter测试则会是一片红, 如果像这样设置了那么会得到如图所示的结果
fallback
fallback和上面案例的blockHandler大同小异
区别:
blockHandler: 传的形参是BlockException流异常
fallback: 传入的是Throwable其他异常
若需模拟: 提供思路, 可以模拟数据库掉线 (即在运行的时候关闭数据库,在进行访问)
对于上述两个案例
在使用上, 两个都大同小异. 实际上
- fallback:若本接口出现未知异常,则调用fallback指定的接口。
- blockHandler:若本次访问被限流或服务降级,则调用blockHandler指定的接口。
所以: fallback一般用于处理业务异常, blockHandler一般被用于处理被限流或服务降级后的处理
总结参考:
- blockHandler
blockHandler仅处理限流异常;
使用blockHandler时,方法签名参数与原方法一致,且必须要在参数的最后位置补充BlockException参数;
若未补充BlockException参数则不生效;
- fallback
fallback可以处理所有类型异常,包括限流异常和业务异常;
使用fallback时,方法签名参数可以与原方法完全一致,或者也接受在参数的最后位置补充Throwable参数;
通过对Throwable参数的类型区分是限流异常还是其他异常;
当同时生效blockHandler和fallback时,限流异常会优先被blockHandler处理而不再进入fallback逻辑;
可查看: Sentinel的blockHandler与fallback-CSDN博客
AOP完成业务异常统一处理
其实本节也是跟上一节应该是父子目录关系, 因为过于重要, 所以提升一个档位, 故位于同级目录
@ControllerAdvice
利用注解采用AOP切面处理Controller中的异常, Advice增强
利用@ExceptionHandler(RuntimeException.class)捕获某异常, 然后包装回送(可以利用@ResponseBody回送JSON数据)
1 | /** |
加上该切面增强之后, 出现的运行时异常都会被切面处理到然后以我们构造的结果集返回, 不会在出现500异常(针对此案例而言)
模拟: 在运行时关闭数据库, 通过Jmiter发送请求, 发现都是绿油油的201, 再也不是红红的500了
此时虽然是完成了业务处理, 这里的处理指返回结果处理, 但是还是不知道在哪里发生了异常, 很不友好, 对此我们引入切面日志记录异常发生处
Aspect
简单的样例, 可拓展: 写成本地日志文件
1 |
|
Sentinel统一异常处理
要知道Sentinel的异常该怎么处理我们首先需要知道他的架构图,
对于Sentinel架构图How Sentinel works #How Sentinel works 关键字处

通过架构图我们可以知道, Sentinel的核心就是将不同的Slot(插槽)按照顺序连接到一起, 这个模式叫做
对于Sentinel的统一异常处理我们需要利用SpringMVC的全局异常处理机制集中处理异常
依赖–增强适配器
1 | <!--将sentinel的BlockException 抛出 到外面统一由 MySentinelExceptionHandler(我们的异常处理)处理 --> |
配置实现
1 | /** |
此时设置好之后, 我们在Sentinel Dashboard对findByPage进行流控设置QPS:1 .
通过Jmiter进行测试(10QPS)
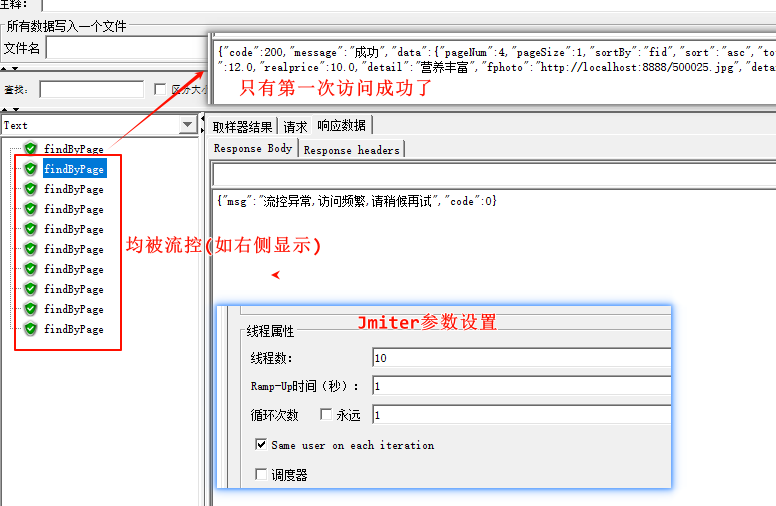
只有第一个访问成功, 其他的均为被流控, 证明这些异常全部到我们设置的MySentinelExceptionHandler了, 其他的异常可以去Dashboard设置即可触发(例如我们去系统规则设置入口QPS:1), 则也会触发相对应的系统异常












